 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepAudio 2.5 Technical Report
May 22, 2026Unified audio-language modeling has emerged as a prominent trend in modern speech systems, promising to bring the reasoning capabilities of large language models to auditory tasks. However, existing unified foundations often struggle to match the depth of specialized systems across automatic speech recognition (ASR), text-to-speech synthesis (TTS), and realtime spoken interaction. Bridging this gap remains an open challenge. This report presents StepAudio 2.5, a unified audio-language foundation model that matches or exceeds specialized systems across all three capabilities. Rather than treating these tasks as architecturally distinct, we operate on the premise that once text and audio share a multimodal representational space, task specialization becomes a matter of operational regimes: data construction, optimization targets, and decoding constraints. Guided by this insight, we advance the post-training paradigm from standard supervised learning to task-tailored Reinforcement Learning from Human Feedback (RLHF), using it as the primary mechanism to define complex optimization targets. We leverage this RLHF-centric alignment, alongside specialized decoding, to shape a shared backbone into three distinct operational modes. Concretely, the ASR branch advances transcription efficiency via verifiable multi-token decoding; the TTS branch achieves controllable, expressive synthesis through preference-based RLHF and context-rich supervision; and the Realtime branch realizes low-latency, persona-consistent dialogue via generative reward modeling within an RLHF framework. On standard benchmarks, StepAudio 2.5 achieves state-of-the-art results across ASR, TTS, and Realtime, demonstrating that a singular audio-language foundation can successfully internalize the distinct deployment objectives of speech understanding, generation, and live interaction.
DuplexSLA: A Full-Duplex Spoken Language Model with Synchronized Speech, Language, and Action
May 20, 2026Recent advances in spoken dialogue language models have shifted from turn-based to full-duplex designs, where the model continuously listens to the user while generating responses. However, existing duplex backbones still lack a native channel for in-conversation planning and tool calling, leaving real-time agentic behaviour either tied to turn boundaries or relegated to an external cascade. We propose DuplexSLA, a native full-duplex Speech-Language-Action foundation model that decodes assistant audio together with a structured action stream on a shared 160 ms chunk timeline. DuplexSLA is built on a dual-stream three-channel formulation: a continuous user audio channel, a discrete assistant audio channel, and a rate-limited textual action channel, all decoded jointly by a single backbone, so that listening, speaking, planning, and tool calling unfold on one shared clock. Two capabilities define the model: (1) semantic-driven turn-taking control, where interruption, pause, and backchannel are handled inside the same backbone instead of by an external semantic VAD; and (2) in-conversation planning and tool calling, where planning text and structured tool calls are emitted on the action channel without halting assistant audio, so that multi-action and backchannel-triggered tool use are interleaved with ongoing speech. To evaluate these capabilities together, we further construct DuplexSLA-Bench, a duplex benchmark covering pause, interrupt, and backchannel turn-taking together with three styles of in-conversation tool calling. Our project page, interactive demos, and the DuplexSLA-Bench evaluation suite are publicly available at https://github.com/hyzhang24/DuplexSLA.
From Drop-off to Recovery: A Mechanistic Analysis of Segmentation in MLLMs
Mar 18, 2026Multimodal Large Language Models (MLLMs) are increasingly applied to pixel-level vision tasks, yet their intrinsic capacity for spatial understanding remains poorly understood. We investigate segmentation capacity through a layerwise linear probing evaluation across the entire MLLM pipeline: vision encoder, adapter, and LLM. We further conduct an intervention based attention knockout analysis to test whether cross-token attention progressively refines visual representations, and an evaluation of bidirectional attention among image tokens on spatial consistency. Our analysis reveals that the adapter introduces a segmentation representation drop-off, but LLM layers progressively recover through attention-mediated refinement, where correctly classified tokens steer misclassified neighbors toward the correct label. At early image token positions, this recovery is bounded by causal attention, which bidirectional attention among image tokens alleviates. These findings provide a mechanistic account of how MLLMs process visual information for segmentation, informing the design of future segmentation-capable models.
Step-Audio-EditX Technical Report
Nov 05, 2025


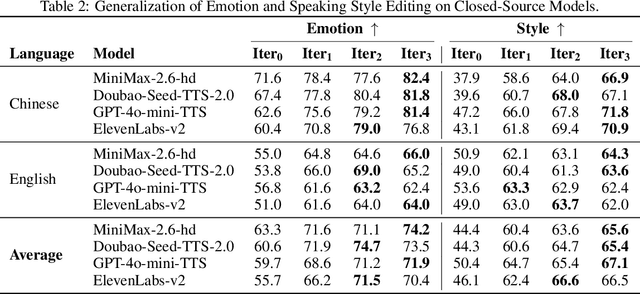
We present Step-Audio-EditX, the first open-source LLM-based audio model excelling at expressive and iterative audio editing encompassing emotion, speaking style, and paralinguistics alongside robust zero-shot text-to-speech (TTS) capabilities.Our core innovation lies in leveraging only large-margin synthetic data, which circumvents the need for embedding-based priors or auxiliary modules. This large-margin learning approach enables both iterative control and high expressivity across voices, and represents a fundamental pivot from the conventional focus on representation-level disentanglement. Evaluation results demonstrate that Step-Audio-EditX surpasses both MiniMax-2.6-hd and Doubao-Seed-TTS-2.0 in emotion editing and other fine-grained control tasks.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025



Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Transferable speech-to-text large language model alignment module
Jun 19, 2024



By leveraging the power of Large Language Models(LLMs) and speech foundation models, state of the art speech-text bimodal works can achieve challenging tasks like spoken translation(ST) and question answering(SQA) altogether with much simpler architectures. In this paper, we utilize the capability of Whisper encoder and pre-trained Yi-6B. Empirical results reveal that modal alignment can be achieved with one layer module and hundred hours of speech-text multitask corpus. We further swap the Yi-6B with human preferences aligned version of Yi-6B-Chat during inference, and discover that the alignment capability is applicable as well. In addition, the alignment subspace revealed by singular value decomposition(SVD) also implies linear alignment subspace is sparse, which leaves the possibility to concatenate other features like voice-print or video to expand modality.
Hard Sample Mining for the Improved Retraining of Automatic Speech Recognition
Apr 17, 2019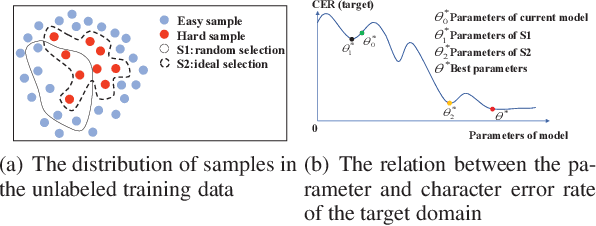
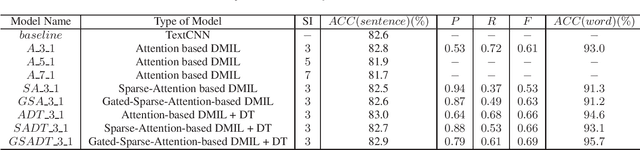
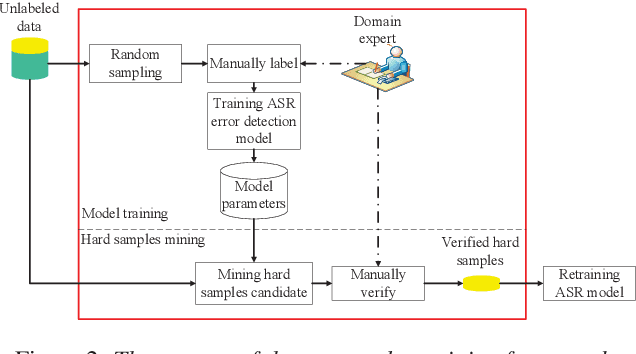

It is an effective way that improves the performance of the existing Automatic Speech Recognition (ASR) systems by retraining with more and more new training data in the target domain. Recently, Deep Neural Network (DNN) has become a successful model in the ASR field. In the training process of the DNN based methods, a back propagation of error between the transcription and the corresponding annotated text is used to update and optimize the parameters. Thus, the parameters are more influenced by the training samples with a big propagation error than the samples with a small one. In this paper, we define the samples with significant error as the hard samples and try to improve the performance of the ASR system by adding many of them. Unfortunately, the hard samples are sparse in the training data of the target domain, and manually label them is expensive. Therefore, we propose a hard samples mining method based on an enhanced deep multiple instance learning, which can find the hard samples from unlabeled training data by using a small subset of the dataset with manual labeling in the target domain. We applied our method to an End2End ASR task and obtained the best performance.